租房問題我們時常遇到,如今數據挖掘技術給租賃市場帶來了新變化。那么,不同地區的租房數據挖掘究竟能給咱們帶來什么好處?下面我們就來深入了解一番。
數據獲取
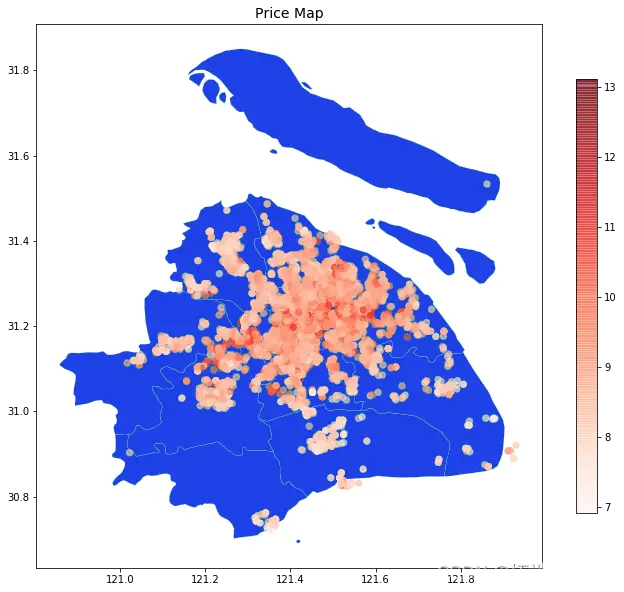
針對北京短租房的研究,學者們聚焦于Airbnb平臺。2019年4月17日,他們收集了北京區域的多種公開信息,包括房源基本信息、租賃時間表、用戶評價以及行政區劃資料等。而身處上海的他們,則運用Python技術,從鏈家網站的.csv文件中提取了租賃數據,為深入分析奠定了數據基礎。
變量處理
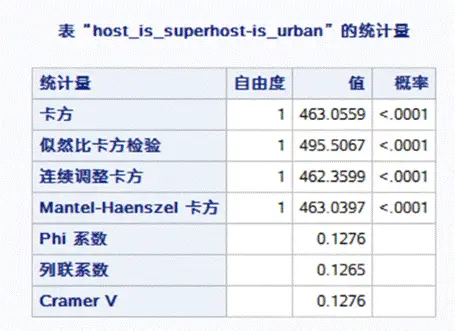
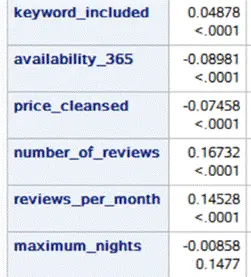
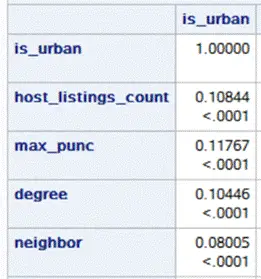
研究將所有變量劃分成離散和連續兩類。分別對這兩類變量運用不同技術進行市區相關性的檢測。同時,將市郊房型以虛擬變量形式展現。房東回應時長、房間種類、房源位置準確性,以及房東是否為高級房東等因素,也都逐一用虛擬變量替換,以方便模型構建。
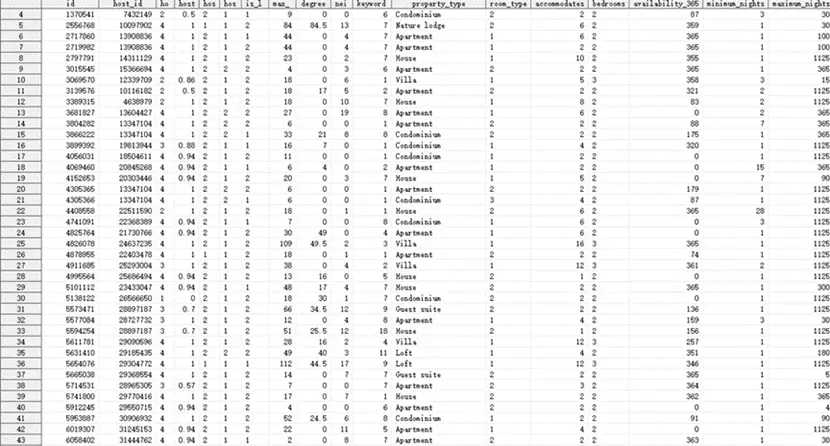
特征轉換
該研究對房源的具體評分進行了轉換處理。考慮到每項評分最高為10分,共有6項評分,為了使這些評分與總分review_scores_rating(滿分100分)的量綱相匹配,我們將每個評分乘以權重10/6,從而得到新的變量review_scores_specific。這種轉換使得數據在模型運算中能更有效地發揮作用。
模型構建

在建立模型的過程中,我們采用邏輯回歸和決策樹兩種方法。在決策樹模型中,內部節點用于記錄分類特征,分支表示判斷結果,而葉子節點則代表最終的分類。此外,我們將評分超過98.5的標記為1,低于98.5的標記為0,這些標記構成了目標變量score_kind。從根節點到葉子節點,形成了一套分類規則。另一方面,我們使用了上海鏈家提供的租房數據,構建了多種模型,包括嶺回歸、Lasso回歸、隨機森林、XGBoost、Keras神經網絡以及kmeans聚類等。

模型優化
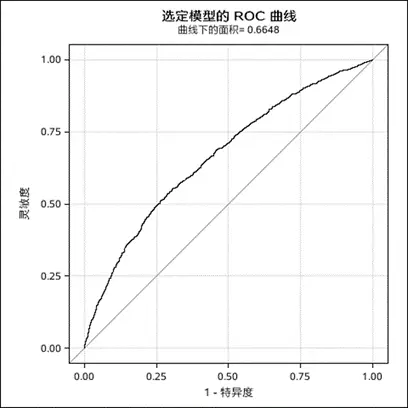
模型優化確實有具體做法。比如在邏輯回歸過程中,會把各個殘差的統計數據導出到res_out數據集中,然后挑選出那些Pearson殘差絕對值超過2的觀測值作為異常數據。這樣的篩選可以提升模型的準確度和可信度,從而使模型在實際應用中發揮更佳效果。
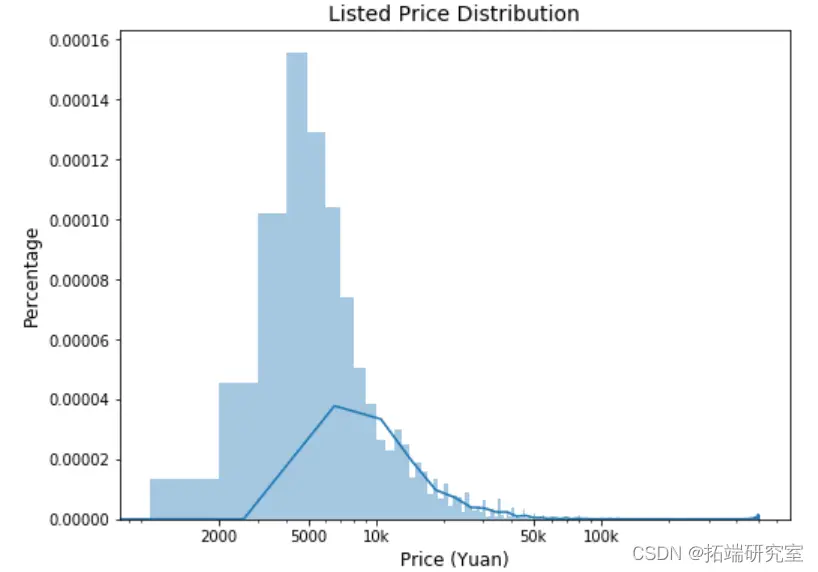
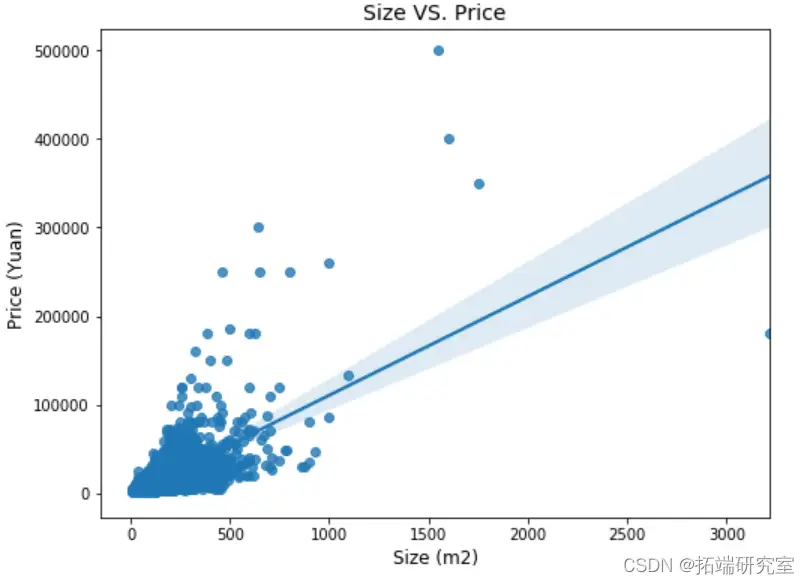
預測效果
預測結果顯示,在城區數據分類中,決策樹法準確率高達76.457%,而在郊區數據分類中,準確率更是達到了85.08%。這一結果充分顯示出決策樹在處理租房數據分類預測方面的優勢,為短租房市場的精準運營和租房價格的合理預估提供了有力的數據支持。
觀察這些數據挖掘所得,你認為在未來的租房市場里,哪個模型可能扮演更重要的角色?歡迎在評論區發表你的看法,同時別忘了點贊并轉發這篇文章!